Auto-Researching Tagore's Songs
by Pradipta Mitra
Rabindranath Tagore wrote roughly 2,000 songs — collectively Rabindra Sangeet. Earlier this year I curated them from widely available public sources into a structured dataset and put it on Hugging Face:
Each row is a song with its Bengali lyrics plus structured metadata: thematic category (পূজা/Devotion, প্রেম/Love, প্রকৃতি/Nature, …), subcategory, Gitabitan serial_number, year of composition (Bengali and Gregorian), raga (melodic mode), and taal (rhythmic cycle). My stated goal at the time was to enable machine-driven analyses of this corpus — and then my day job got in the way and nothing happened.
Karpathy’s autoresearch
In the meantime, Andrej Karpathy released his autoresearch project. He hands an AI agent a deep-learning training setup (data + a training script) and rather general instructions on how it could modify the script to improve the quality of the model it trains. The agent is then simply told to iterate forever — modify code, train for ~5 minutes, keep or discard, repeat. Karpathy reported that the agent found several optimizations he himself had missed — a genuinely impressive feat given his stature as one of the great AI researchers of our time.
Piggybacking on it
It occurred to me that I could piggyback on this. I pointed Claude at my dataset and at Karpathy’s project, and asked it to adapt the “forever” prompt to accomplish what I sadly hadn’t.
The problem domain is different in a few ways. First, there’s no starter script — the agent has to invent each experiment from scratch. Second, the success metric is far more nebulous than “training loss went down”: an analysis has to be statistically significant and “interesting” and “causally plausible”. To support that last criterion, the agent is explicitly allowed to look up information outside the dataset (e.g. the timeline of World War I, or what raga Mallar connotes in Indian Classical music).
The adapted instruction file the agent runs on is program.md. An excerpt:
You are an autonomous research agent. Your goal is to discover interesting, statistically grounded, and narratively meaningful insights from…
Statistical Strength (0–5) … 5: Overwhelming evidence, large effect, robust to methodology choices Narrative Strength (0–5) … 5: Genuinely revelatory — changes understanding of the corpus Verdict: INTERESTING: Both scores ≥ 3 …
FORBIDDEN: Do NOT use large language models (LLMs) for classification, embedding, or feature extraction. The dataset is likely in their training data, making any LLM-based result circular and meaningless. … Stick to classical ML and hand-crafted features.
Every experiment the agent ran, plus its running lab notebook, lives in the repo:
- Repo: https://github.com/pradiptamitra/tagore_auto_analysis/
- The lab notebook:
research_log.md— one structured entry per experiment (hypothesis, method, key finding, p-values, a narrative, and self-assigned scores). It’s the single best file to skim if you want to see the agent think, including the dead ends.
Pleasantly, you can interrupt at any time and interject an idea, and the agent picks it up and keeps running with it. (One of the results below exists only because I did exactly that.)
The analyses
In the end Claude completed nearly 40 experiments. About five or six I find genuinely interesting, including a couple of negative results. Here’s a representative sample.
1. Pronoun usage became more introspective
In Experiment 027, the agent found a moderate but very significant shift in pronoun usage: the first-to-second-person ratio rose over Tagore’s career — the songs became more introspective. From research_log.md:
First person increased (rho=0.149, p=7.6e-13), especially in Puja (rho=0.214, p=6.5e-8). 1st/2nd ratio flipped from 0.85 (1880s) to 2.44 (1910s). … Early Tagore wrote more in the “You” voice — addressing God, the beloved, or the audience. Over time, songs became more “I”-centered — introspective, personal.
This is where I interjected. I asked it to split devotional (Puja) songs from love (Prem) songs and look at the trajectory within each. That forked analysis lives in its own folder, and the result surprised me:
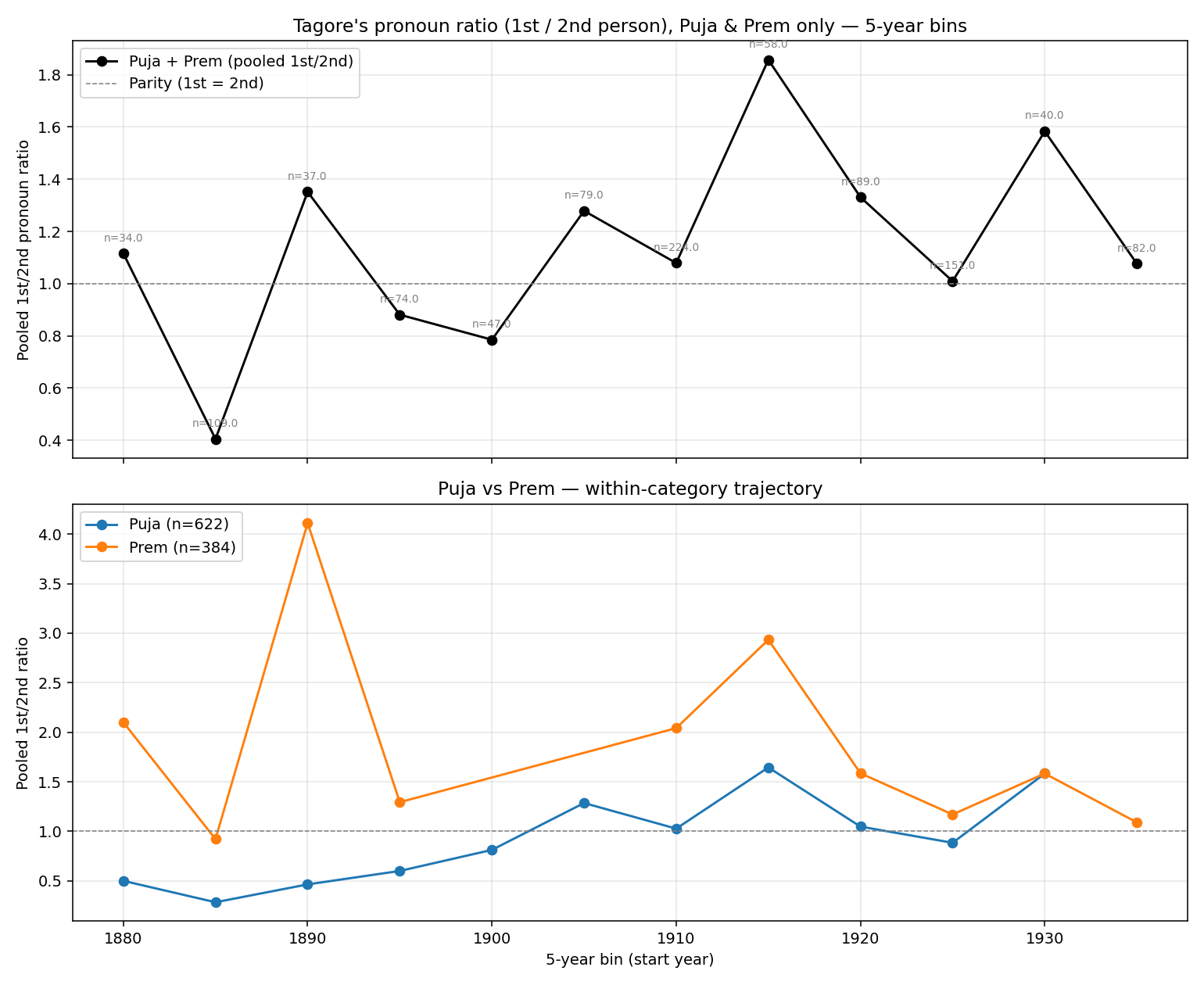
Top: pooled 1st/2nd-person ratio for Puja+Prem, 5-year bins, with the parity line (ratio = 1). Bottom: the two categories separately.
Two clean narratives fell out (from the fork’s findings_puja_prem.md):
- Prem was always 1st-person. Love songs were introspective from the start… (Prem ρ = −0.04, n.s.).
- Puja became more like Prem. Devotional songs started overwhelmingly addressing God in the 2nd person (“তুমি/তব”), then shifted to a balanced/1st-leaning mode where the worshipper’s own self enters the frame. The shift began around 1900–1905 (Puja ρ = 0.165, p = 3.3e-5).
2. Raga cannot be predicted from lyrics (an honest negative result)
I had hoped you could predict a song’s raga (melodic mode) from its lyrics. In Experiment 005 the agent tried and failed:
Best accuracy 16.6% (LR + char n-grams) — essentially at the majority baseline (16.4%). … a meaningful negative result: raga is fundamentally a musical choice, not a textual one.
I pushed it to try harder — different feature representations, including semantic embeddings (with the no-pretrained-LLM caveat respected). In Experiment 037 it closed the question:
Both TF-IDF (18.7%) and embeddings (18.1%) sit at baseline. … Tagore chose ragas based on mood, but the same mood can be expressed in many ragas, and the same raga can carry many moods. The mapping is many-to-many, not one-to-one.
What does survive is a much weaker, aggregate signal. In Experiment 036 the agent found that emotional valence correlates with raga choice in a musicologically coherent way:
Mallar (the monsoon raga) is the only negative-valence raga (−0.51%); Bhairav is brightest (+5.37%), followed by Bahar (the spring raga, +5.15%). Kruskal–Wallis valence p = 0.0001.
Frankly, I find the negative result more interesting than a mediocre classifier would have been.
3. Tala choice simplified sharply between 1909 and 1918
The strongest finding, statistically, concerns taal (rhythmic cycle). The agent’s first pass used raw beat-count as a proxy for “complexity.” I objected — Teentaal has 16 beats but is the most accessible, symmetric taal in Hindustani music — and asked it to build a musicology-grounded classification instead. That combined re-analysis is here. The corrected scale didn’t weaken the finding — it strengthened it. From research_log.md:
Mean rhythmic complexity by decade: 1880s 2.74, 1890s 2.80, 1900s 2.70, then a steep fall — 1910s 1.78, 1920s 1.20, 1930s 1.21. … monotone and very strong (Spearman ρ = −0.53, p = 3.0e-110) … The shape is flat-then-collapse: … only ~17% is attributable to changing genre mix.
In plain terms: between the mid-1900s and the late 1910s — spanning personal bereavement and the First World War — Tagore abandoned the classical rhythmic vocabulary of his youth (Chautal, Dhamar, Jhaptaal, Ektal) and permanently adopted a simple, light, song-oriented idiom (Dadra, Kaharba). With plateaus on each side, this is about as clean a stylistic phase transition as you could hope to see in a creative corpus.
Final thoughts
For an author as exhaustively studied as Tagore, these particular findings might be only moderately interesting — scholars have spent a century with this material. But imagine pointing this at the writers nobody has had the time to study — the poets, lyricists, and essayists in dozens of under-resourced languages. We could go from “almost no one has studied this” to “here are forty falsifiable hypotheses about it” overnight, one literature at a time. The world is our oyster.
All code, the agent’s instruction file, and its full lab notebook: https://github.com/pradiptamitra/tagore_auto_analysis/. Dataset: Pradipta/tagore_songs.